Bryan Caplan
bcaplan@gmu.edu
http://www3.gmu.edu/departments/economics/bcaplan
Econ 637
Spring, 1999
Week 11: Time Series, II: Systems of Simultaneous Equations
- VARs, I: The Basics
- VAR="vector autoregression." VARs are the multivariate version of univariate time series regressions.
- General univariate autoregression simply regresses a single variable y on p lags of y:
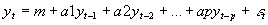
- General VAR works with a vector of k variables Yt=[y1t, y2t, y3t,... ykt].
- In a VAR, this vector Yt is regressed on p lags of Y:
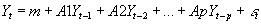 .
.
- Other assumptions of OLS still assumed to hold. E(e
te
s')=W
for s=t, 0 otherwise. Note: W
is k by k.
- A VAR can be written without vector notation as a system of k equations. E.g., suppose p=1, and k=2, the two variables in question being P and M.
- Then one could either write out:
- A system of two equations:
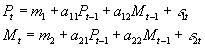
- A single vector equation with
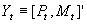 :
: 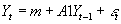 .
.
- A third way to represent the same system:
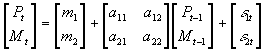
- Just as a univariate autoregression may be stationary or nonstationary, so too may a VAR. A VAR will be stationary so long as the modulus of each of the eigenvalues of A is less than 1. (You may skip discussion of alternative cases in text).
- Brief refresher: eigenvalues are the values of lambda that solve the equation:
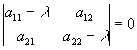
.
- Punchline: So long as VAR is stationary, you can estimate the coefficients and SEs by separately applying OLS to each equation in the system! (This is one of the special cases where SUR and OLS yield identical results).
- VARs, II: Granger Causality and Impulse Response Functions
- The way VARs are set up makes it natural to test for so-called "Granger causality," a misnomer since it has nothing to do with causality. Rather: y2 Granger causes y1 if a regression of y1 on lagged y2 yields a coefficient significantly different from zero.
- A slightly more involved test of pseudo-causality: see if lagged y2 predicts y1, but lagged y1 does not predict y2.
- One interesting thing about VARs (and system of equations more generally) is that even though the system is linear, a disturbance can affect the system in non-linear ways. When you calculate the response of the system to a shock, you are calculating the impulse response function.
- One simple example (from Johnston/DiNardo). Suppose you have a 2-variable, 1-lag VAR:
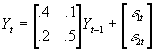 . Ceteris paribus, what happens to the system if at t=0, e
1t=1?
. Ceteris paribus, what happens to the system if at t=0, e
1t=1?
- Implement the ceteris paribus assumption by setting all disturbances except e
1t equal to 0, along with all lags of Yt before t=0.
- Then in t=0,
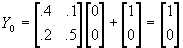 .
.
- But then at t=1,
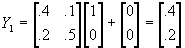 ; at t=2,
; at t=2, 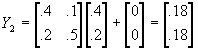 ; at t=3,
; at t=3, 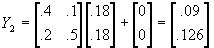 , etc. Thus a single shock to one linear equation set of a "chain reaction" throughout the system.
, etc. Thus a single shock to one linear equation set of a "chain reaction" throughout the system.
- The shock could also have been from an exogenous variable added to the VAR system rather than from the realization of the error term.
- General procedure for calculating ir's:
- Initially set everything equal to 0 except your shock. This includes your lagged Y's for p periods into the past.
- Calculate Y0 using the equations of your linear system.
- Calculate subsequent values of Y by plugging past values of Y into your linear system. When programming, an iterative procedure is natural: calculate Y0, set Y-1, Y-2, Y-p to all zeros. Then set up a loop to have the computer calculate Y1 using Y0 through Y-p+1, then calculate Y2 using Y1 through Y-p+2, etc.
- Standard Error Bands
- Once you calculate and graph your impulse-response function, you might like to get some notion of the precision with which your i-r has been estimated.
- So, people frequently add "SE bands" to show upper and lower bounds for the probable response of the system to a given shock.
- SE bands are derived from the original coefficients and their SEs. Essentially, you are imagining how the system would behave if it turned out that your estimates were different in plausible ways.
- Several different ways to calculate SE bands. Easiest if your software isn't smart enough to do the work for you:
- Use approximation for the variance of a function of a vector of coefficients b: f'(b)'*V(b)*f'(b). V is the variance-covariance matrix for b, and f'(b) is the matrix of numerical derivatives for a given ir.
- My version is Eviews is smart enough to calculate SE bands for VARs but not for systems of equations in general.
- VARs and Causation
- How do VARs solve the simultaneity problem endemic to the estimation of systems of equations? Some misunderstanding to the contrary, VARs alone do nothing to solve this problem.
- VARs usefully summarize data, just as regressing Q on P may usefully summarize data. Both may be useful for predictions, but they tell us nothing about causality.
- One popular way to try to convert VARs into tools of causal inference has been to use "orthogonalized innovations." (See text for more detailed treatment).
- With the orthogonalized innovations, a shock to the 1st error implies a shock to the 2nd; but a shock to the 2nd does not imply a shock to the first. Many have found this econometric procedure to be causally instructive.
- If you think that money contemporaneously causes prices to increase, but don't think that prices contemporaneously causes money to increase, then put M first and P second. Then a shock to P won't contemporaneously change M, but a shock to M will contemporaneously change P.
- Ex: Bernanke-Blinder (1992) - solving simultaneity of non-policy and policy variables by assuming either no contemporaneous impact of non-policy on policy, or no contemporaneous impact of policy on non-policy.
- But: this procedure generates great controversy, because you typically have to assume what you want to prove - i.e., the direction of causation!
- When VARs have a causal interpretation, they are often called "structural" VARs, or SVARs. Using orthogonalized innovations is perhaps the most popular strategy for getting SVARs.
- Systems of Simultaneous Equations and Causation
- Regular VARs have no causal interpretation; SVARs do.
- Instead of assuming orthogonalized innovations to give your VAR a causal interpretation, you can simply apply standard principles of identification, learned in weeks 8-9.
- Once you estimate all of the equations in your system, you can then calculate the impulse response function, SE bands, and give your VAR a causal interpretation.
- The same applies if you have a system of time series equations that don't look like VARs. Use standard principles of identification to give your results a causal interpretation. Then, calculate the ir function and SE bands.
Appendix: Pooled Time Series
- Pooled Time Series, Fixed Effects, and Random Effects
- Recall that you have pooled time series when you observe a number of different subjects repeatedly over time. E.g., you have data for 20 countries over 20 years.
- Main advantage: Easy way to increase your total number of observations and thereby get more precise estimates.
- Simplest use of pooled time series: Just estimate using OLS and the same set of variables you would use for a single variable. I.e., suppose that on a single variable you would estimate Yt=b1+b2*Yt-1+b3*Xt. Then just "stack" all of your Y and X data into a BigY and BigX variable, being excruciatingly careful with lags.
- Fixed effects estimation essentially adds subject (person, country, firm, etc.) and/or time (year, month, quarter, etc.) dummies, then runs OLS.
- This just allows each country and/or year to have its own constant. The same result can be achieved by demeaning.
- Disadvantage of fixed effects estimation: you can't recover the effects of time-invariant explanatory variables. E.g. square mileage of U.S. states does not change, so if you do fixed effects estimation you have no way to figure out effect of mileage (on your computer, you'll probably get a singularity error).
- Why is this a problem? Lots of seemingly important factors don't vary over time, or at least can't be measured as varying over time: e.g., economic system, location...
- Ex: West and East Germany.
- Random effects estimation is a third possible tactic. With random effects estimation, e.g. country-specific intercepts are random variables instead of constants. For details, see text. This allows time-invariant variables to matter.